| Flink + StarRocks+ Dinky 极速一站式分析平台 | 您所在的位置:网站首页 › flinksql cdc › Flink + StarRocks+ Dinky 极速一站式分析平台 |
Flink + StarRocks+ Dinky 极速一站式分析平台
|
大数据开发
大数据开发发展阶段: 大数据程序语言写业务逻辑阶段 大数据 SQL 化阶段 在多数据平台独立分析的阶段 Starocks、Dataworks、Streamx 、Dinky 等统一平台化,一站式阶段
Flink CDC 目前只支持 flink 1.14.* ,暂不支持 1.15.* 安装 到 flink 命名空间:kubectl -n flink apply -f flink-session-only.yaml 会自动创建 Flink Session Deployment(部署) 和 对应的 Service (服务发现 ) 安装 Dinky 到 K8S --- apiVersion: apps/v1 kind: Deployment metadata: labels: app: flink-dlink name: dlink spec: selector: matchLabels: app: flink-dlink template: metadata: labels: app: flink-dlink spec: containers: - image: anjia0532/dlink:v0.6.6-1 name: dlink volumeMounts: - mountPath: /opt/dlink/config/application.yml name: admin-config subPath: application.yml volumes: - configMap: name: dlink-config name: admin-config --- apiVersion: v1 kind: ConfigMap metadata: name: dlink-config data: application.yml: |- spring: datasource: url: jdbc:mysql://mysql-headless.mysql:3306/dlink?useUnicode=true&characterEncoding=UTF-8&autoReconnect=true&useSSL=false&zeroDateTimeBehavior=convertToNull&serverTimezone=Asia/Shanghai&allowPublicKeyRetrieval=true username: dlink password: dlink driver-class-name: com.mysql.cj.jdbc.Driver application: name: dlink # flyway: # enabled: false # clean-disabled: true ## baseline-on-migrate: true # table: dlink_schema_history # Redis配置 #sa-token如需依赖redis,请打开redis配置和pom.xml、dlink-admin/pom.xml中依赖 # redis: # host: localhost # port: 6379 # password: # database: 10 # jedis: # pool: # # 连接池最大连接数(使用负值表示没有限制) # max-active: 50 # # 连接池最大阻塞等待时间(使用负值表示没有限制) # max-wait: 3000 # # 连接池中的最大空闲连接数 # max-idle: 20 # # 连接池中的最小空闲连接数 # min-idle: 5 # # 连接超时时间(毫秒) # timeout: 5000 server: port: 8888 mybatis-plus: mapper-locations: classpath:/mapper/*Mapper.xml #实体扫描,多个package用逗号或者分号分隔 typeAliasesPackage: com.dlink.model global-config: db-config: id-type: auto configuration: ##### mybatis-plus打印完整sql(只适用于开发环境) # log-impl: org.apache.ibatis.logging.stdout.StdOutImpl log-impl: org.apache.ibatis.logging.nologging.NoLoggingImpl # Sa-Token 配置 sa-token: # token名称 (同时也是cookie名称) token-name: satoken # token有效期,单位s 默认10小时, -1代表永不过期 timeout: 36000 # token临时有效期 (指定时间内无操作就视为token过期) 单位: 秒 activity-timeout: -1 # 是否允许同一账号并发登录 (为true时允许一起登录, 为false时新登录挤掉旧登录) is-concurrent: false # 在多人登录同一账号时,是否共用一个token (为true时所有登录共用一个token, 为false时每次登录新建一个token) is-share: true # token风格 token-style: uuid # 是否输出操作日志 is-log: false --- apiVersion: v1 kind: Service metadata: name: flink-dlink spec: ipFamilies: - IPv4 ipFamilyPolicy: SingleStack ports: - name: http port: 8888 protocol: TCP targetPort: 8888 selector: app: dlink type: ClusterIP注意修改 ConfigMap 里的 dlink 链接的 MySQL 的地址,用户名,密码,以及执行 github.com/DataLinkDC/… 里的 dlink.sql (第一次执行) 和 dlinkmysqlcatalog.sql(第一次执行),如果是已经存在了,只是要升级,执行 dlink_history.sql kubectl -n flink apply -f dlink.yaml可以使用 Idea 里的 Kubernates, Nocalhost, 或者 VS Code 里的 Kubernates, Nocalhost 或者命令行程序 k9s 或者 kubectl 把 dlink 和 flink job UI 的端口转出来。 整库同步需要确保 dlink 所在的 MySQL 的 my.conf 开了 binglog ,并且 格式为 ROW。演示 整库同步 dlink 的所有表同步到 cdc-test 中。在 dlink 的 MySQL 数据库中创建一个名为 cdc-test 的库。 EXECUTE CDCSOURCE cdc_mysql1 WITH ( 'connector' = 'mysql-cdc', 'hostname' = 'mysql-headless.mysql', 'port' = '3306', 'username' = 'dlink', 'password' = 'dlink', 'checkpoint' = '3000', 'scan.startup.mode' = 'initial', 'parallelism' = '1', 'table-name' = 'dlink\..*', 'sink.url' = 'jdbc:mysql://mysql-headless.mysql:3306/cdc-test?characterEncoding=utf-8&useSSL=false', 'sink.username' = 'dlink', 'sink.password' = 'dlink', 'sink.connector' = 'jdbc', 'sink.sink.db' = 'cdc-test', 'sink.table.prefix' = '', 'sink.table.lower' = 'true', 'sink.table-name' = '${tableName}', 'sink.driver' = 'com.mysql.jdbc.Driver', 'sink.sink.buffer-flush.interval' = '2s', 'sink.sink.buffer-flush.max-rows' = '100', 'sink.sink.max-retries' = '5' )打开 Dlink Web 添加 K8S Session 集群,添加 作业,复制 CDCSource SQL 保存,并执行、或者异步提交。
打开 Flink UI 看看执行情况。
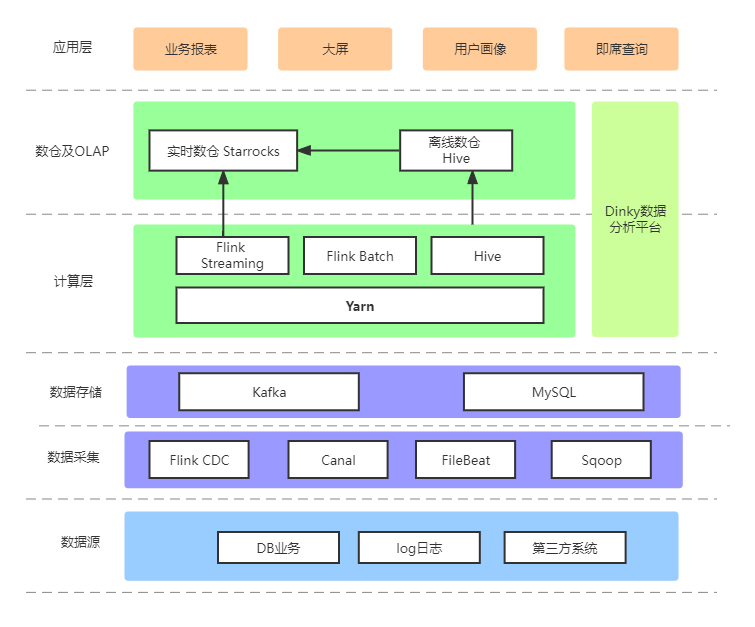
####MySQL 表名查询 SQL SELECT GROUP_CONCAT(CONCAT(table_schema,"\\.",table_name)) from `information_schema`.`TABLES` WHERE table_schema='dlink'; ## 结果为 dlink\.dlink_alert_group,dlink\.dlink_alert_history,dlink\.dlink_alert_instance,dlink\.dlink_catalogue,dlink\.dlink_cluster,dlink\.dlink_cluster_configuration,dlink\.dlink_database,dlink\.dlink_flink_document,dlink\.dlink_history,dlink\.dlink_jar,dlink\.dlink_job_history,dlink\.dlink_job_instance,dlink\.dlink_savepoints,dlink\.dlink_schema_history,dlink\.dlink_sys_config,dlink\.dlink_task,dlink\.dlink_task_statement,dlink\.dlink_task_version,dlink\.dlink_user,dlink\.metadata_column,dlink\.metadata_database,dlink\.metadata_database_property,dlink\.metadata_function,dlink\.metadata_table,dlink\.metadata_table_property SELECT GROUP_CONCAT( DISTINCT CONCAT(table_schema,"\\..*") ORDER BY table_schema ) from `information_schema`.`TABLES`; ## 结果为 canal_manager\..*,cdc-test\..*,datax_web\..*,dlink\..*,information_schema\..*,mysql\..*,performance_schema\..*,sys\..* 离线计算采用 sqoop 将 MySQL 数据按照 T+1 的方式,每天加载到 Hive 做一些维表字段的冗余;另外一些 MySQL 全量数据和 Hive 通过 Flink Batch 同步到 Starrocks。其中 MySQL 全量跑批是通过 Flink Batch 5 分钟跑批(涉及到特殊场景的表)。 实时计算MySQL 业务数据部分采用 Dinky 整库同步全量 + 增量的方式同步,部分采用 Canal + Kafka + Flink 增量和 Starrocks MySQL 外部表全量的方式同步,以达到实时更新的目的,写入 Starrocks 的主键模型表;行为日志通过 FileBeat + Kafka + Flink 的方式写入 Starrocks 的明细表。 统一数据分析平台Dinky 提供了 Flink 上的批处理和流计算能力,以及外部数据库查询与操作的能力,使得我们的开发效率进一步提升。此外还可以直接在 Dinky 进行数据分析和 ETL 处理,避免了在服务器上部署各种脚本。 数据模型选择Starocks 的数据模型表是一种以 key-value 键值对存在的列式存储。当前支持的模型有明细模型(Duplicate Key)、聚合模型(Aggregate Key)、更新模型(Unique Key)和主键模型(Primary Key)。数据模型的应用场景可以参考 Starrocks 官网的数据模型介绍。根据我司业务报表需求对 Delete,Update 操作比较频繁,其次对于商城系统的行为数据要求实时同步为用户画像做沉淀。因此目前采用了主键模型(Primary Key)和明细模型(Duplicate Key)做支撑。 整库同步 对于数据同步,初期调研的时候有 3 种方案: Flink CDC Canal + Kafka + Flink Canal + Kafka + Routine Load下面分别说下 3 种方案各有优缺点 Flink CDC 优点:支持全量和增量,并且支持断点续传和 ETL,目前支持的数据源也越来越丰富; 缺点:一张表对应一个 JDBC 事务,如果连接数过多,容易对业务库造成压力。不支持整库同步。 Canal + Kafka + Flink 优点:当时考虑到业界的一种通用方案 ; 缺点:只支持增量,全量数据需要另外脚本实现。 Canal + Kafka + Routine Load 优点:简化额外组件,可以很方便在 Starrocks 做数据同步; 缺点:在 Starrocks 2.1 之前的版本对主键模型支持不完善。 基于以上几种方案在前期从 Flink CDC 到 Canal + Kafka + Flink 再到 Canal + Kafka + Routine Load 的不同程度迁移,出现了很多坑。目前 Dinky 社区开发了基于 Flink CDC 整库同步的功能后,经过多方面和社区的沟通,Flink CDC 整库同步已在线上平滑迁移运行,也极大降低了对业务库的压力。 Dinky 整库同步Dinky 定义了 CDCSOURCE 整库同步的语法,该语法和 CDAS 作用相似,可以直接自动构建一个整库入仓入湖的实时任务,并且对 source 进行了合并,不会产生额外的 MySQL 及网络压力,支持对任意 sink 的同步,如 kafka、doris、hudi、JDBC 等。其原理是采用只构建一个 source,然后根据 schema、database、table 进行分流处理,分别 sink 到对应的表。 Dinky 整库同步语法 EXECUTE CDCSOURCE jobname WITH ( 'connector' = 'mysql-cdc', 'hostname' = '192.168.0.2', 'port' = '3306', 'username' = 'root', 'password' = '123456', 'checkpoint' = '3000', 'scan.startup.mode' = 'initial', 'parallelism' = '1', 'table-name' = 'test\.student,test\.score', 'sink.connector' = 'starrocks', 'sink.jdbc-url' = 'jdbc:mysql://192.168.0.3:19035', 'sink.load-url' = '192.168.0.3:18035', 'sink.username' = 'root', 'sink.password' = '123456', 'sink.sink.db' = 'qhc_ods', 'sink.table.prefix' = 'ods_bak_', 'sink.table.lower' = 'true', 'sink.database-name' = 'qhc_ods', 'sink.table-name' = '${tableName}', 'sink.sink.properties.format' = 'json', 'sink.sink.properties.strip_outer_array' = 'true', 'sink.sink.max-retries' = '10', 'sink.sink.buffer-flush.interval-ms' = '15000', 'sink.sink.parallelism' = '1' ) 外部表统一分析Starocks 除自身的几种数据模型外,还提供了对外部数据源的支持,如 MySQL、Hive、Elasticsearch、Hudi 等。 目前离线计算维度表通过 Hive 外部表,每天凌晨跑一次全量。对于第三方数据是存在与 MySQL 业务库,因一些特殊原因,无法开启 binlog,只能通过准实时的方式,每 2 小时跑一次批。 目前所有的外部表都是通过在 Dinky 之上做同步,极大的降低了开发成本。需要注意的一点是目前 Dinky 只支持部分 Starocks 的语法,如 INSERT,TRUNCATE 等。对于 CREATE EXTERNAL 语法创建外部表还不支持。因此 DDL 语法在 MySQL 客户端执行,INSERT,TRUNCATE 在 Dinky 执行。 Hive 外部表 -- 创建一个名为 hive0 的 Hive 资源 CREATE EXTERNAL RESOURCE "hive0" PROPERTIES ( "type" = "hive", "hive.metastore.uris" = "thrift://bigdata1:9083" ); -- hive外部表 CREATE EXTERNAL TABLE `sta_dim_employee_dwd` ( `id` bigint(20) NULL COMMENT "", `performance_id` bigint(20) NULL COMMENT "", `goods_type` int(11) NULL COMMENT "", `goods_type_refine` int(11) NULL COMMENT "", `goods_specs` varchar(65533) NULL COMMENT "" ) ENGINE=HIVE COMMENT "PARTITION BY ()" PROPERTIES ( "database" = "dws", "table" = "dim_employee_dwd", "resource" ="hive0", "hive.metastore.uris" = "thrift://bigdata1:9083,thrift://bigdata2:9083" ); MySQL 外部表 CREATE EXTERNAL TABLE `sta_assassin_employee` ( `id` largeint(40) NOT NULL COMMENT "主键", `old_id` varchar(65533) NULL COMMENT "", `tenant_id` varchar(65533) NULL COMMENT "租户ID", `leader_id` largeint(40) NULL COMMENT "直属上级", `code` varchar(65533) NULL COMMENT "职员工号" ) ENGINE=MYSQL COMMENT "MYSQL" PROPERTIES ( "host" = "127.0.0.1", "port" = "3306", "user" = "root", "password" = "123456", "database" = "employee", "table" = "assassin_employee" ); 集群配置配置 yarn Per-Job 模式 进入注册中心 -> 集群管理 -> 集群配置管理 -> 新建
修改提交 FlinkSQL 的 Jar 文件路径 进入系统设置 -> Flink 设置-> 修改 与 HDFS 的 jar 相呼应文件地址选择合适的版本复制到 hdfs 上。
FlinkCDC 整库入仓 StarRocks 任务开发流程: 编写 FlinkSql 代码 创建源库 目标库 DDL 执行模式选择 YarnPer-Job 点击右上方小火箭(提交任务到集群) Dinky 与 FlinkWebUI 查看任务运行状态 登录 StarRocks 查看数据库数据
也可以不用同步数据到 StarRocks,减短数据加工的链路。 利用 StarRocks 多引擎的外表查询功能,外表 join Hive,外表 join TIDB,外表 join MySQL 等 利用 StarRocks 强悍的性能,输出实时报表、离线报表 |







【本文地址】